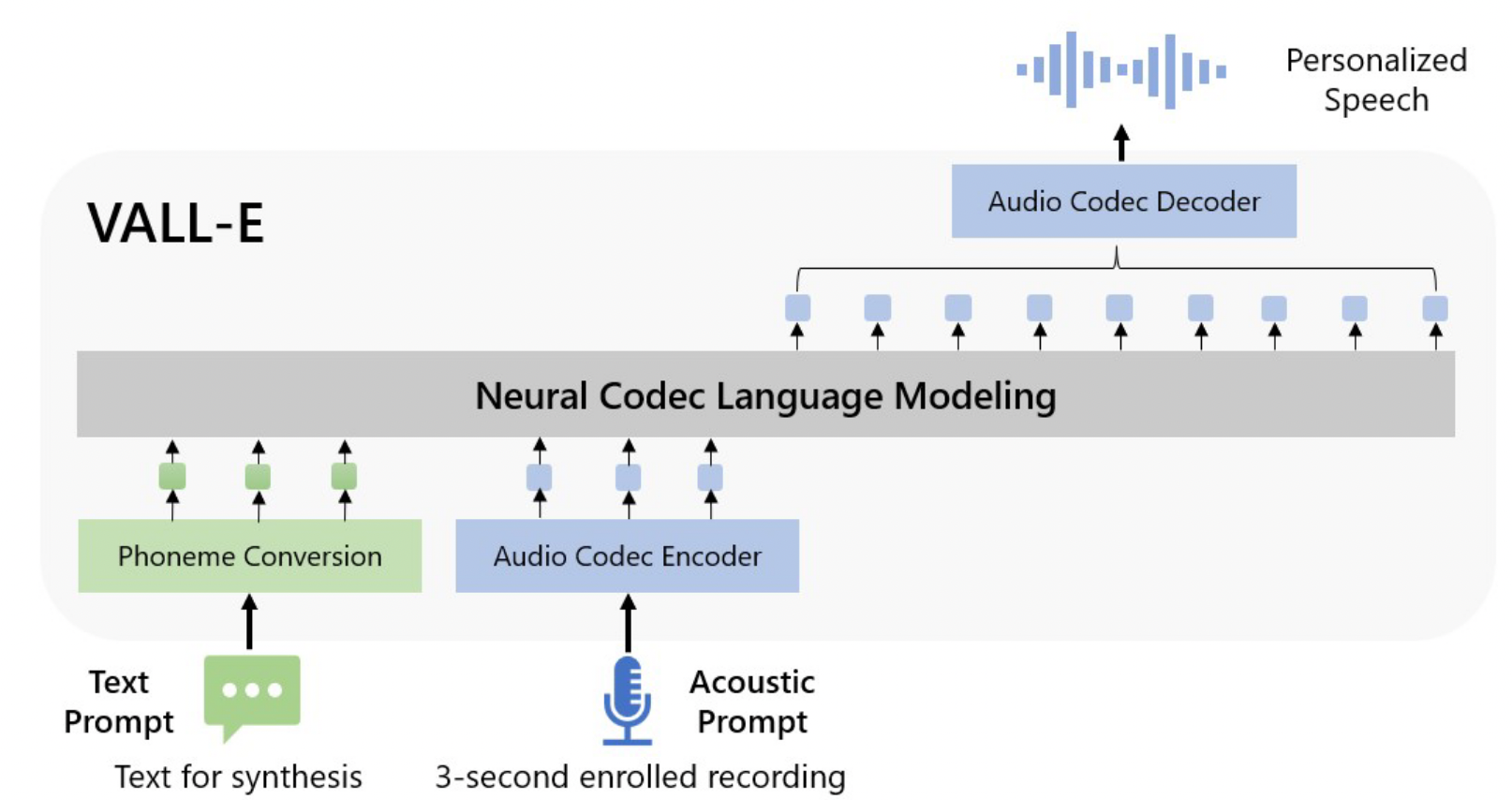
VALL-E
本文最后更新于:2023年2月10日 下午
VALL-E
模型
使用60k小时英语语音训练,使得模型出现上下文学习能力。只需要3秒特定录音,就可以学习到说话人的说话方式,甚至是背景音。
demo演示:https://valle-demo.github.io/
音频量化 Speech Quantization
对于常见的一秒音频,16位,48kHz,意味着需要每个step有\(2^{16}=65536\)个值,整个序列长度接近5万。语音量化的目的是压缩这两个数值。
Wavenet中曾使用\(\mu\)-law变换可以使用256个值重建高质量音频,压缩一半,但没有减少序列长度。
后面出现了矢量量化(vector quantization),应用在vq-wav2vec、HuBERT。
文章采用AudioLM的方法,神经编码解码器模型(neural codec models),优点如下:
- 在低比特率下表现比传统音频编解码器更好。
- 包含说话人信息和声学信息,HuBERT做不到保存说话人信息。
- 有学者提出的现有的解码器,用于将离散标记转换为波形,不用设计解码器。🤣
- 可以做到减少时间序列长度。
文章采用预训练的神经音频编解码器模型EnCodec作为tokenizer,生成声学代码矩阵(acoustic code matrix)。EnCodec是一种卷积编码器-解码器模型,其输入和输出均为可变比特率的24kHz音频。其编码器将24kHz的输入波形生成75Hz的嵌入,采样率降低了320倍。每个嵌入都通过残差矢量量化(RVQ)建模,八个量化器每个有1024个条目。
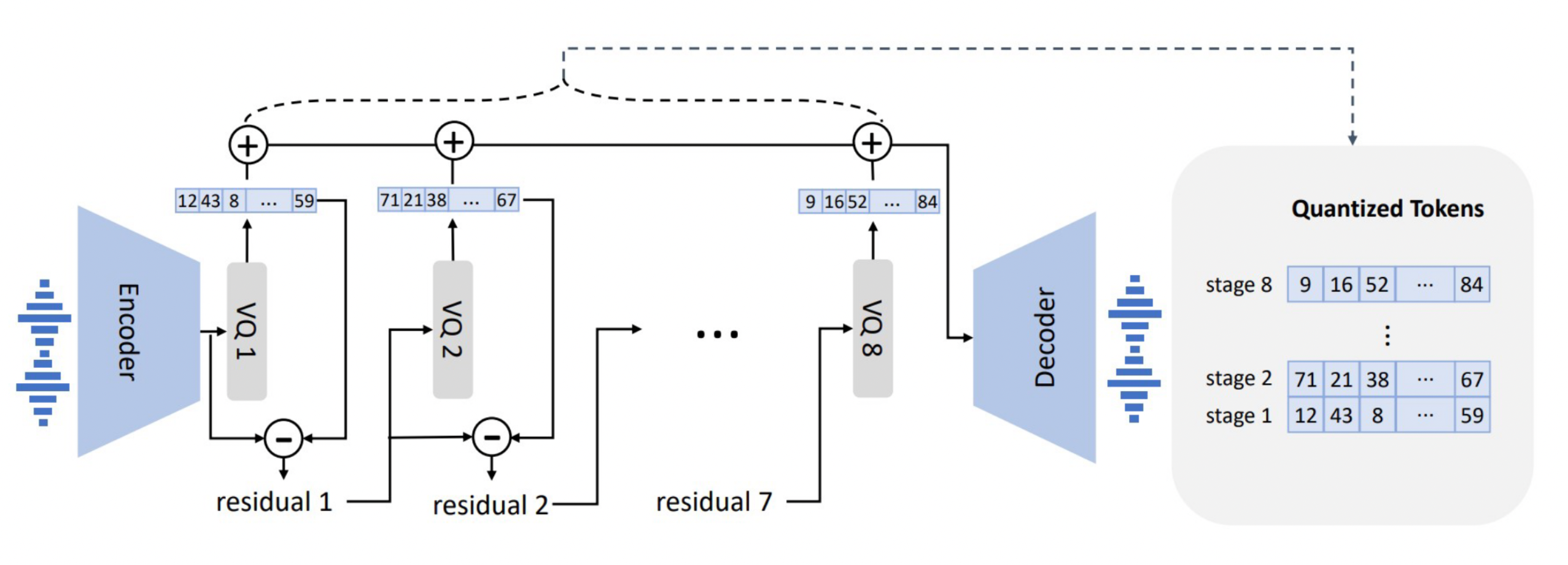
对于VQ1使用AR学习到重要的说话人特征,VQ2-8使用NAR学习其他特征。
模型
优化目标:\(\max p(C|x,\tilde C)\)
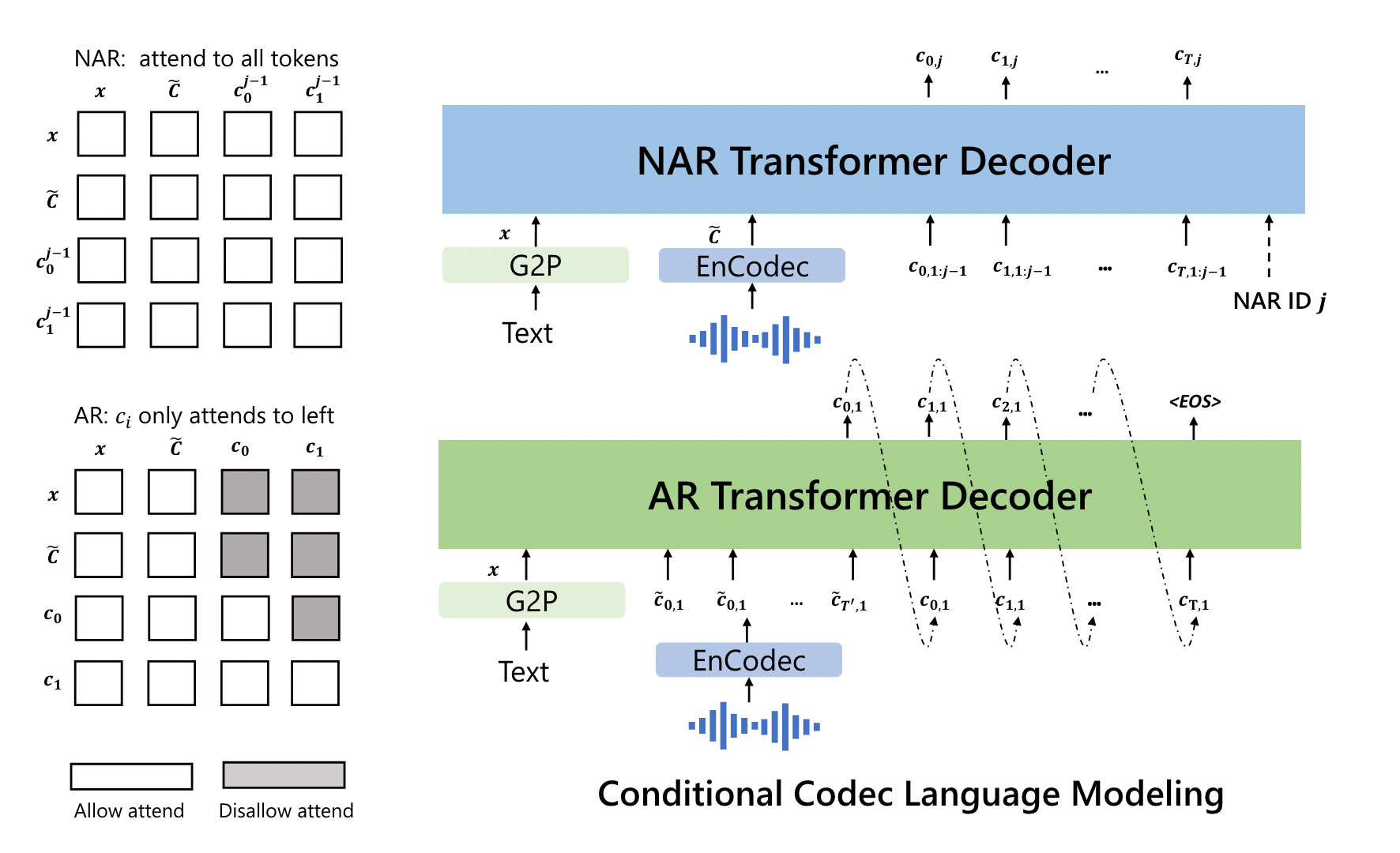
推理
将文本转换为音素序列,并将登记的录音编码为声学矩阵,形成音素提示和声学提示。声学提示可能与要合成的语音在语义上相关,也可能不相关,导致两种情况:
- VALL-E:只学习prompt语音的声学条件,按照文本生成语音。
- VALL-E-continual:按照完整prompt语音转录的文本作为音素提示,使用语音的前3秒作为声学提示,生成的语音语义上接着prompt语音。
数据
LibriLight包含英语有声读物60K小时无标记语音,说话人数量约7000
使用Kaldi的ASR模型,为无标记语音数据生成音素和对齐。
将平均长度为60秒的音频随机裁剪为10-20秒的随机长度,其对应的音素序列作为prompt。在NAR中的prompt会使用同一段话中的3秒随机音频。
16个 NVIDIA TESLA V100 32GB,每个GPU的批量大小为6k声学标记,800k步。使用AdamW优化器优化模型,前32k步更新的学习率预热到 5 × 10−4 的峰值,然后对其进行线性衰减。
分析
- 多样性丰富:原本的mel谱图生成基于每个步骤的重建,其随机性较差,由于VALL-E使用采样的方式生成离散标记,相同文本的输出不同,其多样性丰富。
- 能保持环境音:作者认为,VALL-E的数据集声学条件更多,当prompt带有混响,baseline得到的是干净的声音,VALL-E可以得到相同的混响效果。
- 能保持说话人的情绪:emotional。可以在0-shot条件下保留prompt中的情绪。
- 鲁棒性有待提升:由于VQ1是自回归模型,其中的transformer注意力无序,也没有增加约束,导致在合成结果中出现不清楚、遗漏和重复的问题。
- 数据覆盖有限:由于是有声读物,口音没有覆盖完全,并且只有阅读风格,需要扩大覆盖范围。
- 模型的滥用风险:伪造政客、电信诈骗等应用较为危险。类似于google的AudioLM可能需要同时推出一个分类器用于区分检测VALL-E的合成语音。