富有表现力的语音合成系统(Expressive TTS)
本文最后更新于:2023年4月10日 下午
富有表现力的语音合成系统
Tacotron-GST
在Tacotron引入了全局风格标签(Global Style Token,GST)。模型包括reference encoder,style attention,style embedding
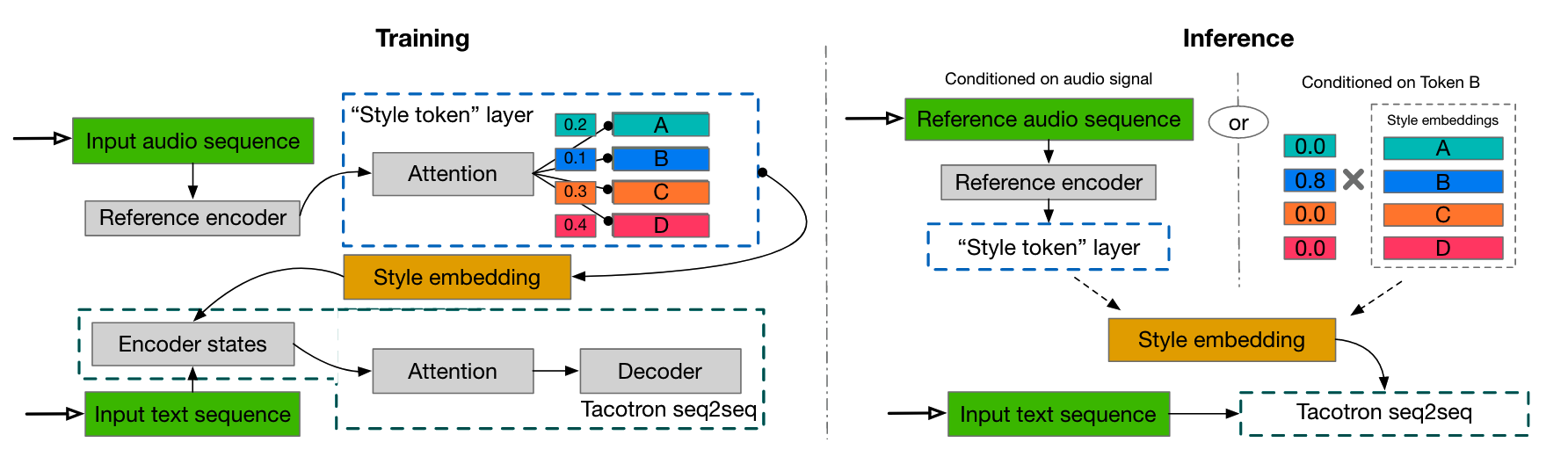
StyleToken-TTS
在数据集上增加风格标签,代表话语风格的短语或词,例如情感、意图和语调。由于风格是用自然语言标记的,因此控制说话风格是直观和可解释的。
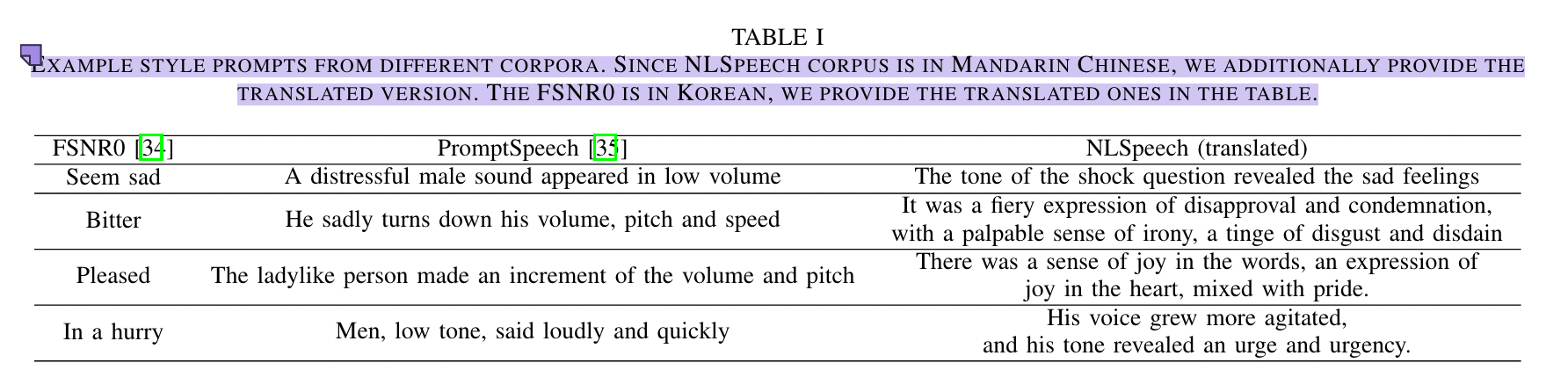
使用的韩语数据集FSNR0,内容为三元组 {speech, transcript, style tag} ,有 327 个风格标签,包括各种情绪、意图、语音语调和速度。
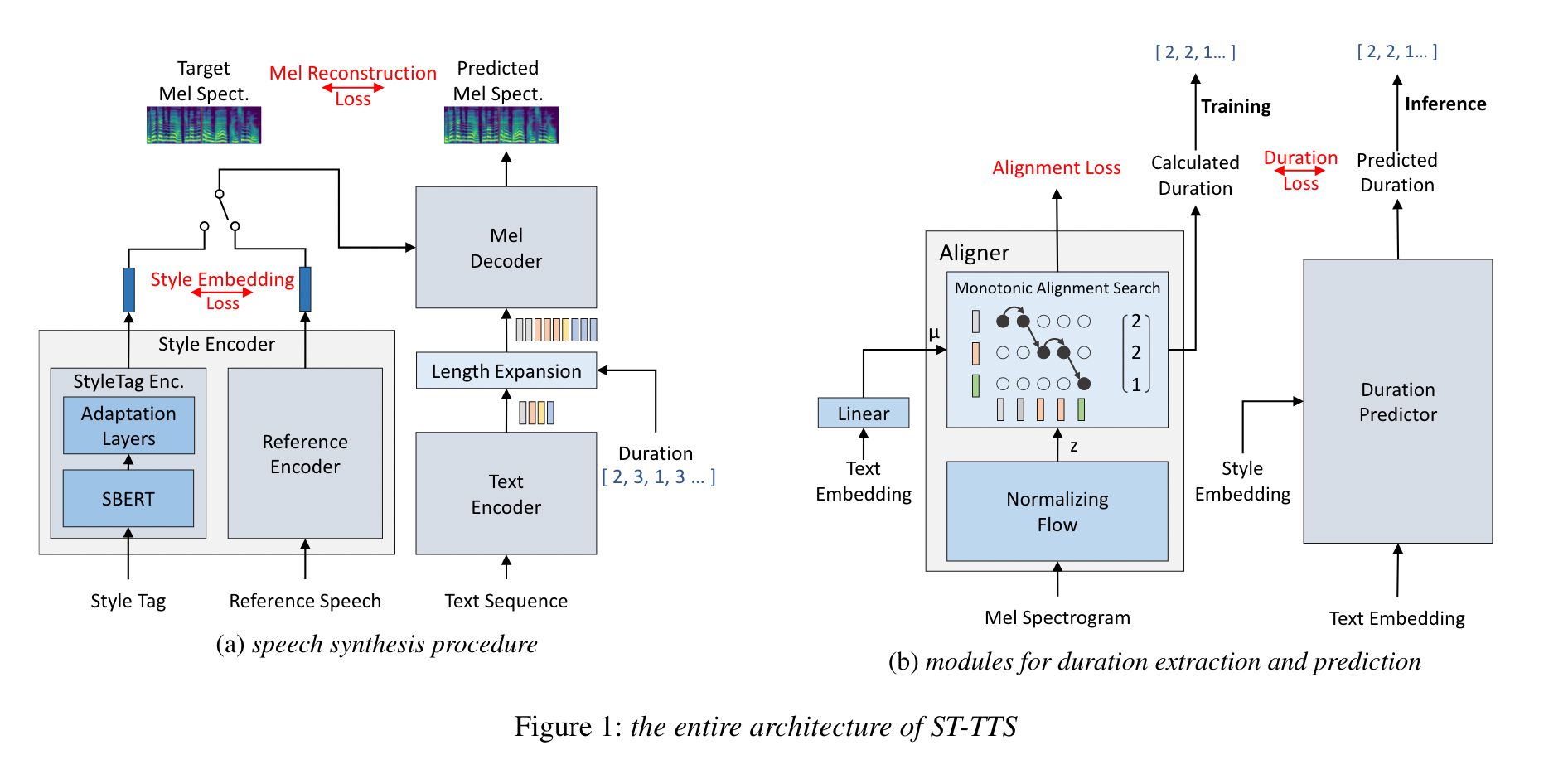
PromptTTS
使用微软的TTS合成语音自建数据集,在LibriSpeech的真人数据上做验证。
其风格提示词假定有五个风格相关内容,如高声调、女声
用[CLS]Token学习隐藏的风格表示,BERT经过微调,用于输出五个风格相关特征
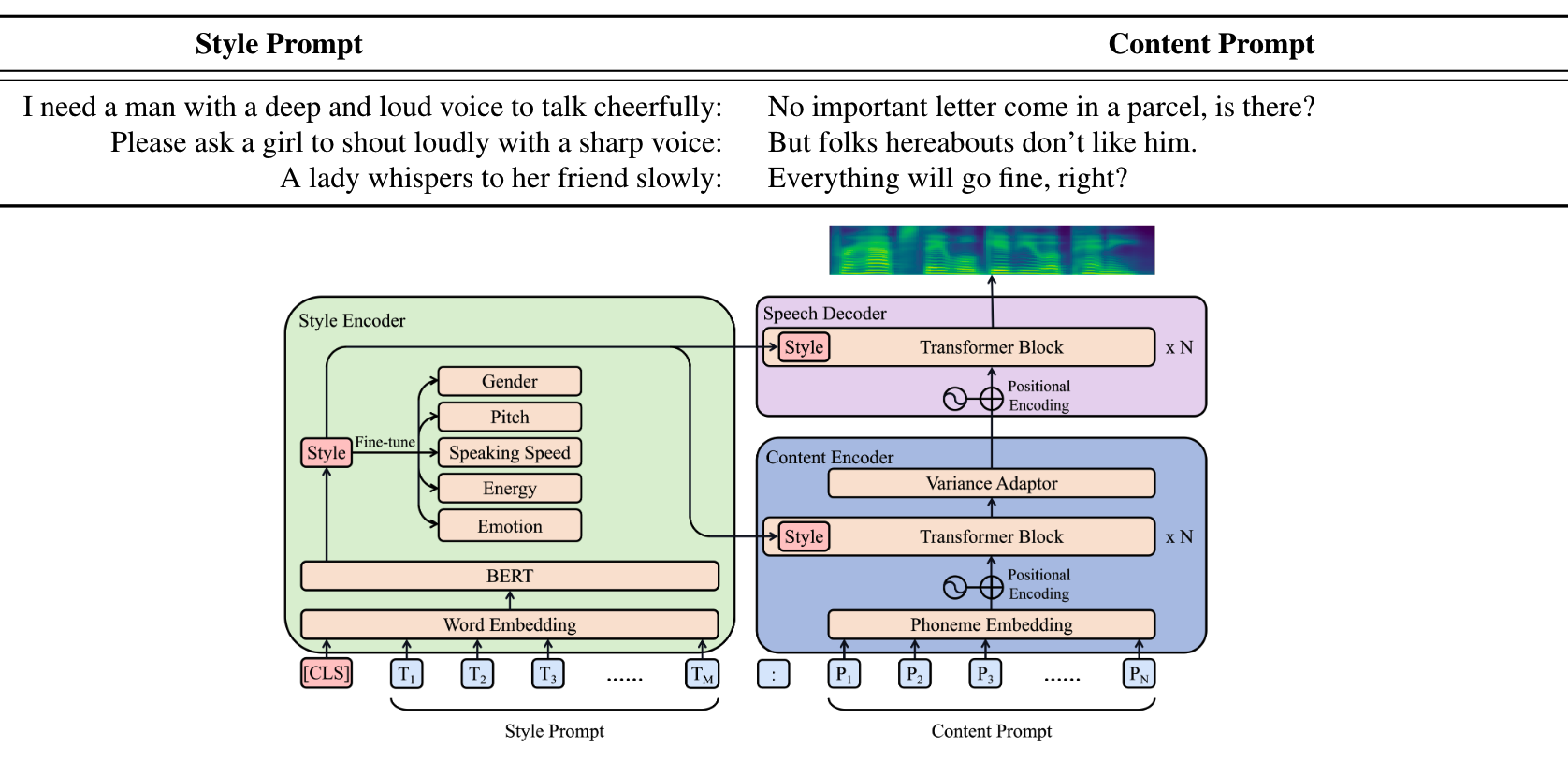
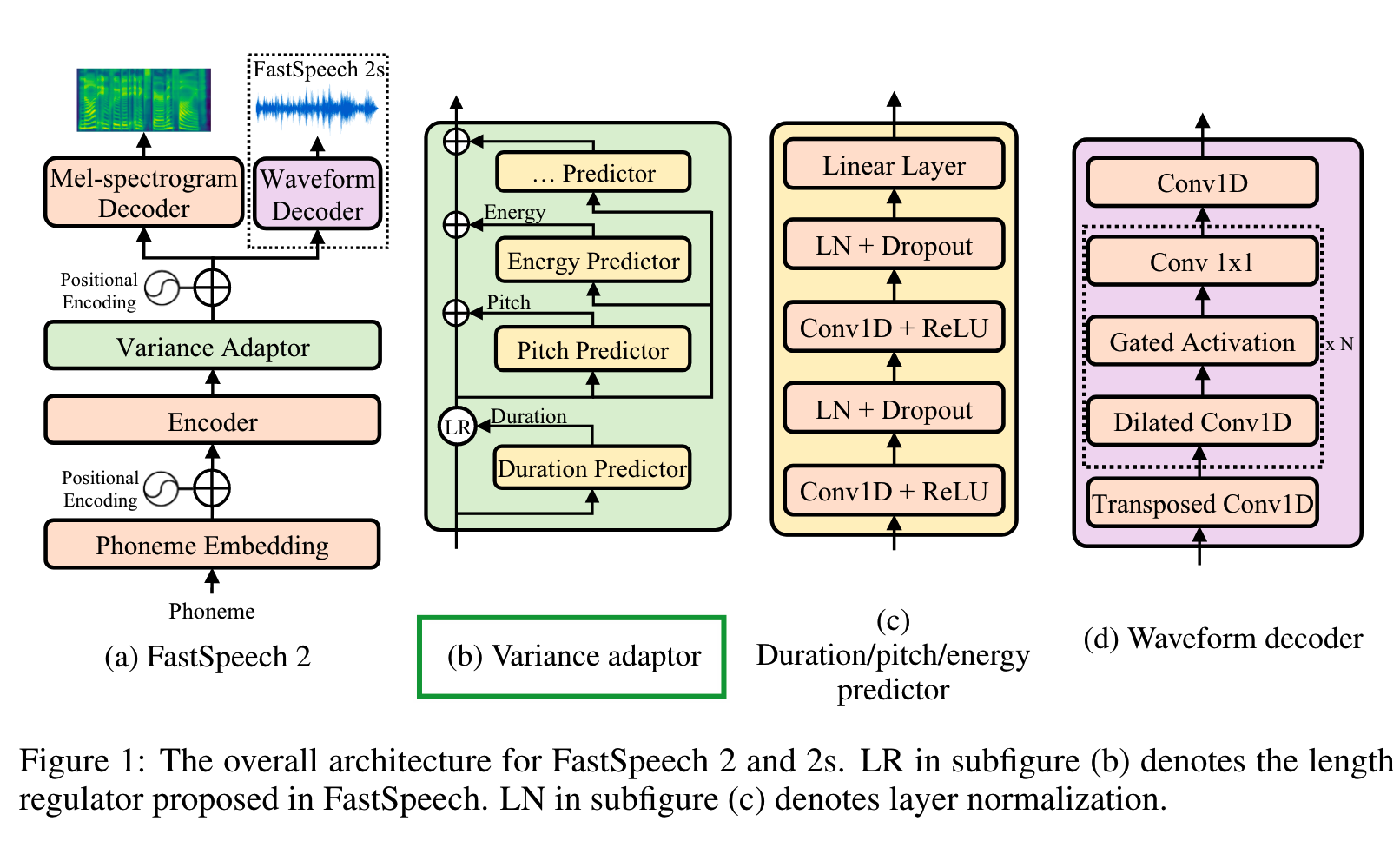
其中Content Encoder顶层的Variance Adaptor来自FastSpeech2,用于预测持续时间、音高、能量等。
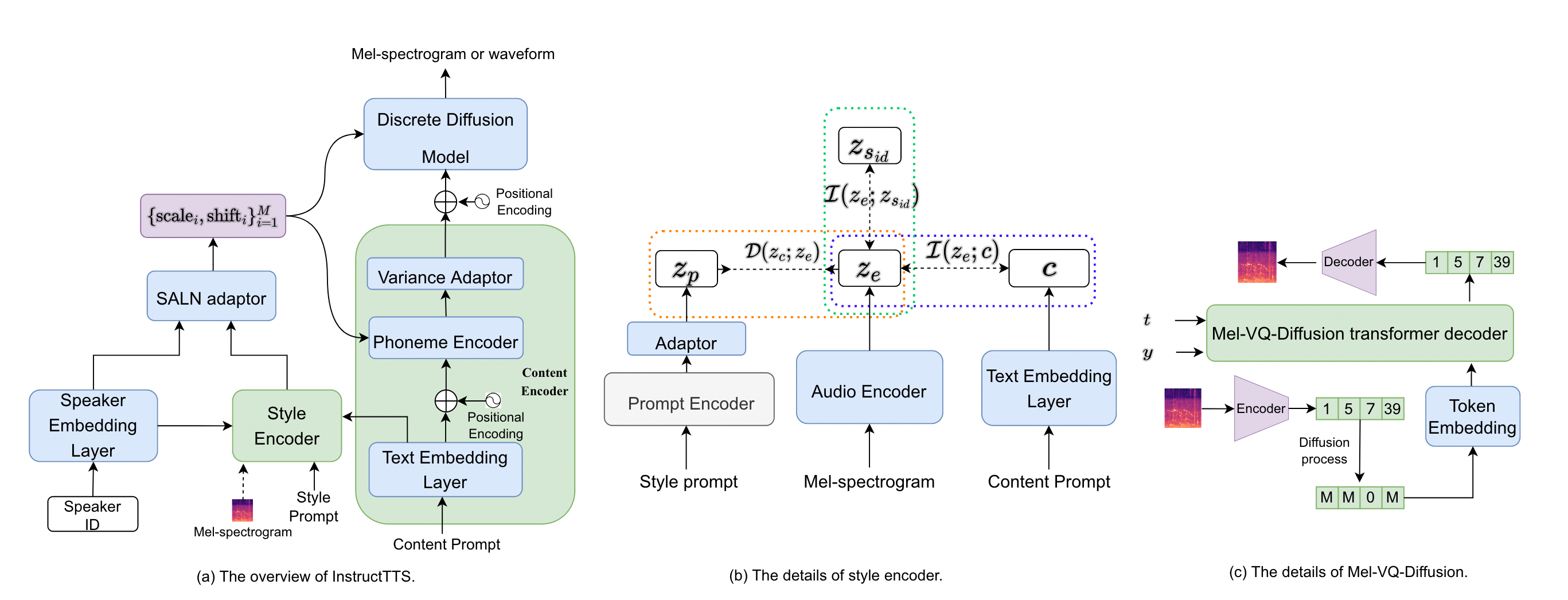
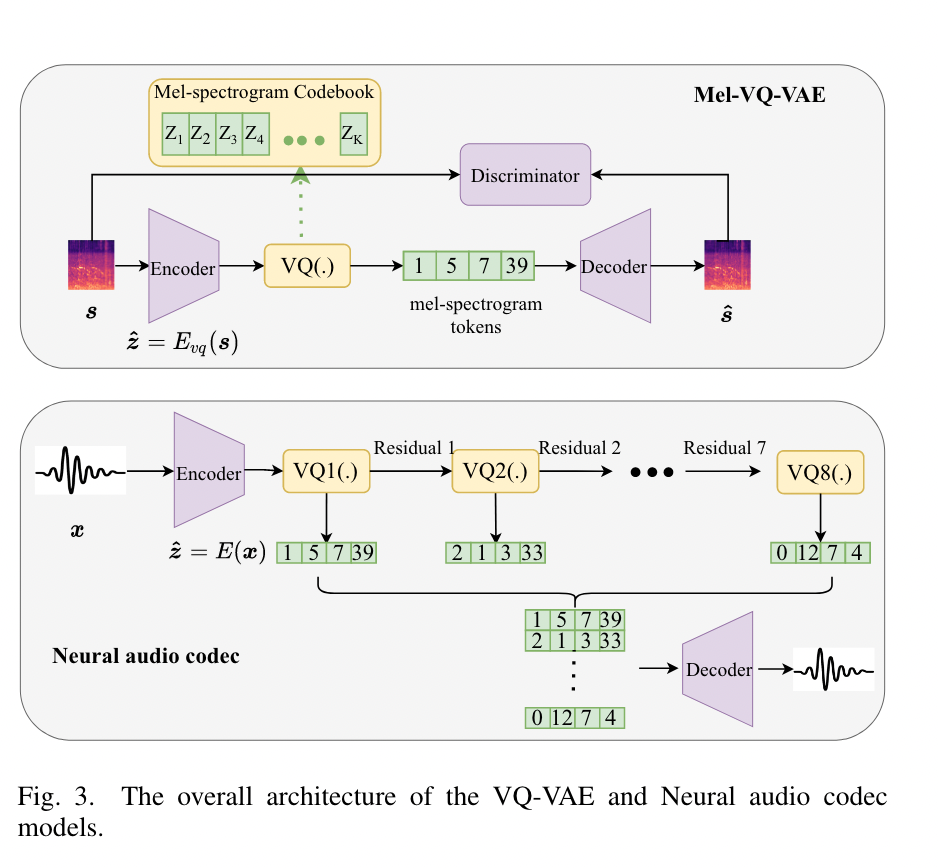
InstructTTS
香港中文大学+腾讯AI Lab合作
demo地址:http://dongchaoyang.top/InstructTTS/
使用自然语言作为提示,指导语音合成的情绪,提示句包含整体感知情绪、话语情感水平、话语风格,每条语音由五个人写出提示句。NLSpeech内部数据集时长约44小时。
富有表现力的语音合成系统(Expressive TTS)
https://ash-one.github.io/2023/02/10/expressive-tts/