本文最后更新于:2023年3月25日 晚上
前言
项目工程地址:https://github.com/Ash-one/ChineseBert-finetuned-NER
chatGPT的大火让很多NLP工作者的研究都陷入僵局,NER这种传统任务对于这种LLM已经可以说是小菜一碟。
NewBing进行ner
虽然没能力搞个GPT出来,搞个简单的Bert微调还是可以做到的。
本文对于NER命名实体识别任务,使用复旦大学的fastNLP工具包快速完成Bert微调和预测任务,还实现了Bert+BiLSTM+CRF的模型提高预测准确率,最终部署在服务器上可视化呈现。
结果展示
fastNLP文档 和gitee仓库 最近更新在五个月前,还比较活跃。fastNLP在手册上有序列标注的源码实现 ,本文基于此进行改写。
数据预处理
使用内置的dataloader加载Weibo数据集
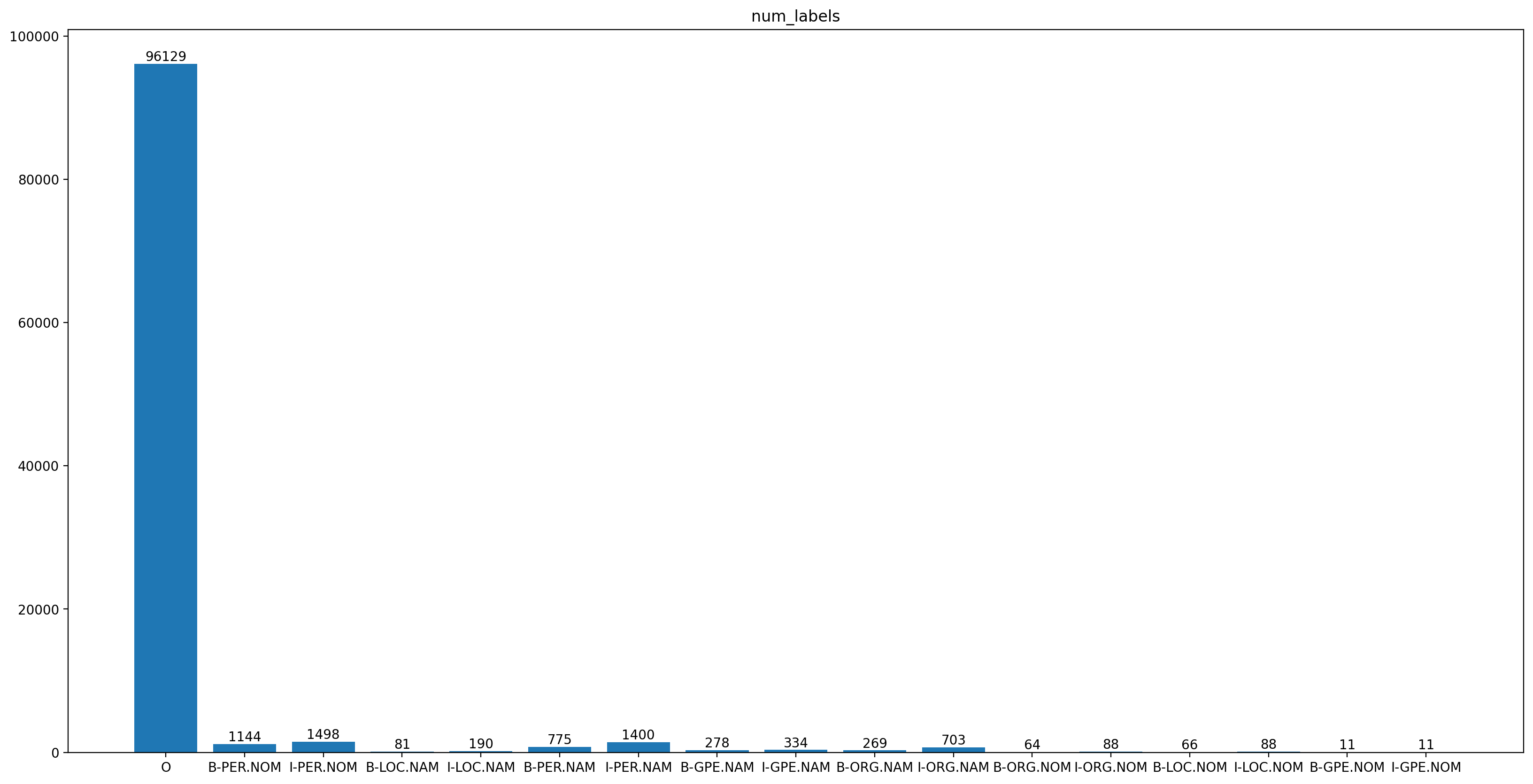
fastNLP自带库中有许多内置数据集,这里选择微博数据集展示,其实体类别分为人物,机构组织,地址和地缘政治实体四个类别,且每个类别可细分为特指(NAM,如“张三”标签为“PER.NAM”)和泛指(NOM,如“男人”标签为“PER.NOM”)。总数据量1890条。
地区名特指,如深圳
B-GPE.NAM I-GPE.NAM
地名特指,如华克山庄
B-LOC.NAM I-LOC.NAM
地名泛指,如寺庙
B-LOC.NOM I-LOC.NOM
组织名特指
B-ORG.NAM I-ORG.NAM
组织名泛指
B-ORG.NOM I-ORG.NOM
人名特指,如方进玉
B-PER.NAM I-PER.NAM
人名泛指,如男人
B-PER.NOM I-PER.NOM
其他
O
17个标签的分布如图所示:
数据集标签总览
接下来开始使用fastNLP库的loader下载并加载数据到data_bundle中。
1 2 3 4 from fastNLP.io import WeiboNERLoaderprint (data_bundle)print (data_bundle.get_dataset('train' )[:4 ])
data_bundle和它的名字一样,是训练集、验证集、测试集的打包,需要分别提取。
1 2 3 4 5 6 7 8 9 10 11 12 13 In total 3 datasets:270 instances.270 instances.1350 instances.[ '科' , '技' , '全' , '方' , '位' , '资' , ... | [ 'O' , 'O' , 'O' , 'O' , 'O' , 'O' , 'O' , '... | | [' 对', ' ,', ' 输', ' 给', ' 一', ' 个', ... | [' O', ' O', ' O', ' O', ' O', ' O', ' B-PER... |[ '今' , '天' , '下' , '午' , '起' , '来' , ... | [ 'O' , 'O' , 'O' , 'O' , 'O' , 'O' , 'O' , '... | | [' 今', ' 年', ' 拜', ' 年', ' 不', ' 短', ... | [' O', ' O', ' O', ' O', ' O', ' O', ' O', ' ... |
计算数据集中的属性
使用BertTokenizer和BPE算法处理文本,得到input_ids|input_len | first| seq_len | new_target这几列,其中first表示bpe算法的结果,在后面的模型中会使用,这里使用new_target作为最终label的编码表示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from fastNLP.transformers.torch import BertTokenizerfrom fastNLP import cache_results, Vocabularydef process_data (data_bundle, model_name ):def bpe (raw_words ):0 ]1 for word in raw_words:False )len (bpe)return {'input_ids' : bpes, 'input_len' : len (bpes), 'first' : first, 'seq_len' : len (raw_words)}'raw_chars' , num_proc=4 )None , unknown=None )'train' ), field_name='target' )'target' , new_field_name='new_target' )'new_target' )return data_bundle, tokenizer'hfl/rbt3' )print (data_bundle)print (data_bundle.get_dataset("train" )[:4 ])
可以看出input_len比seq_len多两个,分别是一头一尾两个token。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [08:23 :40 AM] INFO In total 3 datasets: 1356482314.py:35 ---------------- +---------------- +---------------- +- 1356482314.py:36 ---------- +---------------- +--------- +--------------- ---------------- +---------------- +---------------- +- ---------- +---------------- +--------- +--------------- ... | ['O', 'O', ... | [101, 4906,... | .. | 26 | [0, 0, 0, 0... ... | ['O', 'O', ... | [101, 2190,... | .. | 15 | [0, 0, 0, 0... ... | ['O', 'O', ... | [101, 791, ... | .. | 79 | [0, 0, 0, 0... ... | ['O', 'O', ... | [101, 791, ... | .. | 18 | [0, 0, 0, 0... ---------------- +---------------- +---------------- +- ---------- +---------------- +--------- +---------------
将计算后的数据放入dataloader
制作dataloader方便遍历,bs大小256大约占用20G显存。
对输入和输出分别进行padding
1 2 3 4 5 6 7 8 from fastNLP import prepare_torch_dataloader256 )for dl in dataloaders.values():'input_ids' , pad_val=tokenizer.pad_token_id)'new_target' , pad_val=-100 )
Bert模型微调
Bert模型的提供者们往往提供的是预训练模型,我们可以在预训练模型之后添加其他模型或层来改变输出,而将Bert的部分当作对文字编码的部分使用。这里后接MLP作为NER任务的baseline做参考,然后在Bert后添加BiLSTM和CRF进行对比。
设计Bert+MLP模型
fastNLP的模型基于torch,所以写法是一样的;同时内置的transformer库也是huggingface的直接迁移,用法上完全一样,只是默认的模型加载路径和huggingface的transformer库不一样,如果同时使用可能会发现缓存位置不同而重复下载。
这里使用hfl/rbt3这个中文Bert模型,大小约500M,BertModel.from_pretrained()函数会从远程拉取该模型保存在缓存后加载(复旦源,国内很快)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import torchfrom torch import nnfrom fastNLP.transformers.torch import BertModelfrom fastNLP import seq_len_to_maskimport torch.nn.functional as Fclass BertNER (nn.Module):def __init__ (self, model_name, num_class ):super ().__init__()0.3 ),def forward (self, input_ids, input_len, first ):1 ).repeat(1 , 1 , last_hidden_state.size(-1 ))1 , index=first)1 :-1 ] return {'pred' : pred}def train_step (self, input_ids, input_len, first, target ):'pred' ]1 , 2 ), target)return {'loss' : loss}def evaluate_step (self, input_ids, input_len, first ):'pred' ].argmax(dim=-1 )return {'pred' : pred}'hfl/rbt3' , len (data_bundle.get_vocab('new_target' )))
forward函数和torch写法相同,train_step会被后面声明的trainer对象调用,计算训练的每一步loss,evaluate_step会被后面声明的evaluator对象调用,相当于预测函数,返回的是预测标签对应的数字index。
设计Bert+BiLSTM+CRF模型
这里需要考虑的是三个模型之间的输入输出要匹配,去掉了bpe算法部分方便将bert结果输入LSTM,另外在CRF模型的输入中mask大小不是Bert输入的带有前后标记的attention
mask,而是最简单的长度mask,所以重新制作了mask输入crf中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import torchfrom torch import nnfrom fastNLP.transformers.torch import BertModelfrom fastNLP import seq_len_to_maskimport torch.nn.functional as Ffrom fastNLP.modules.torch import ConditionalRandomFieldclass BertBilstmCrfNER (nn.Module):def __init__ (self, model_name,num_class, embedding_dim = 768 ,hidden_size=512 ,dropout=0.5 ):super ().__init__()2 ,True ,True )2 , num_class)def forward (self, input_ids, input_len,target=None ):with torch.no_grad():1 :-1 ]1 )2 )if target is None :return {'pred' : pred}else :return {'loss' : loss}def train_step (self, input_ids, input_len, target ):return self(input_ids, input_len,target)def evaluate_step (self, input_ids, input_len ):return self(input_ids, input_len)'hfl/rbt3' , len (data_bundle.get_vocab('new_target' )))
开始训练
这里我们准备Trainer对象的各个参数,具体细节不做深入解释,看名字很好理解。
其中Trainer对象默认调用数据的标签的表头是target,所以这里需要这个函数将我们自己设计的new_target列调整。 如果你和我一样是按照官方文档的写法,直接调用官方loader加载,在这里就需要这个函数,因为在文档里的ipython结果是从文件读取的,列名称和loader加载的不同。
实际训练中CRF模型训练需要调大学习率,否则转移矩阵的学习结果会很差,实际使用的lr为2e-2,是mlp模型的一千倍。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from torch import optimfrom fastNLP import Trainer, LoadBestModelCallback, TorchWarmupCallbackfrom fastNLP import SpanFPreRecMetric2e-5 )"f" : SpanFPreRecMetric(tag_vocab=data_bundle.get_vocab('new_target' )),def input_mapping (data ):'target' ] = data['new_target' ]return data'train' ], optimizers=optimizer,'dev' ],50 , callbacks=callbacks,'f#f' ,device='cuda' ,driver="torch" ,input_mapping=input_mapping)
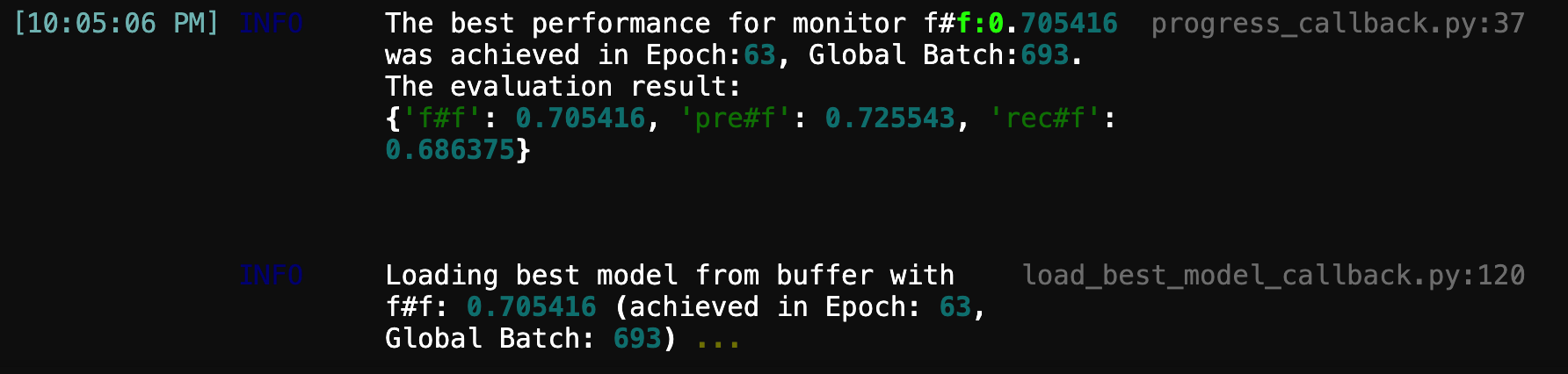
Bert+MLP模型:50轮跑完结果如下,自动将最佳模型加载到model对象,这里在验证集上的F1值有0.573477,不算很高,因为Bert直接微调效果有限,但是预测结果有一定的参考价值了。
1 2 3 4 5 6 7 8 [11:36:55 AM] INFO The best performance for monitor f
模型保存和加载
训练好模型之后需要进行保存,这里使用torch的保存,fastNLP也有自己的保存方法,是相同的。
1 2 3 import os'rbt3-mlp-ner.pth' )'rbt3-mlp-ner.pth' )
使用模型预测
由于后续需要部署到服务器上进行使用,这里需要构建好整个预测流程,fastNLP工具包本身没有这个功能,只是用来快速构建模型验证,但是预测流程本身与训练流程相同,并不复杂。
将预测文本放入dataset,再放入databundle,经过bpe计算,
放入dataloader,交给evaluator调用预测函数得到预测结果。
构建dataset
其实是构建一个只有一条数据的的dataset再放入databundle对象中。
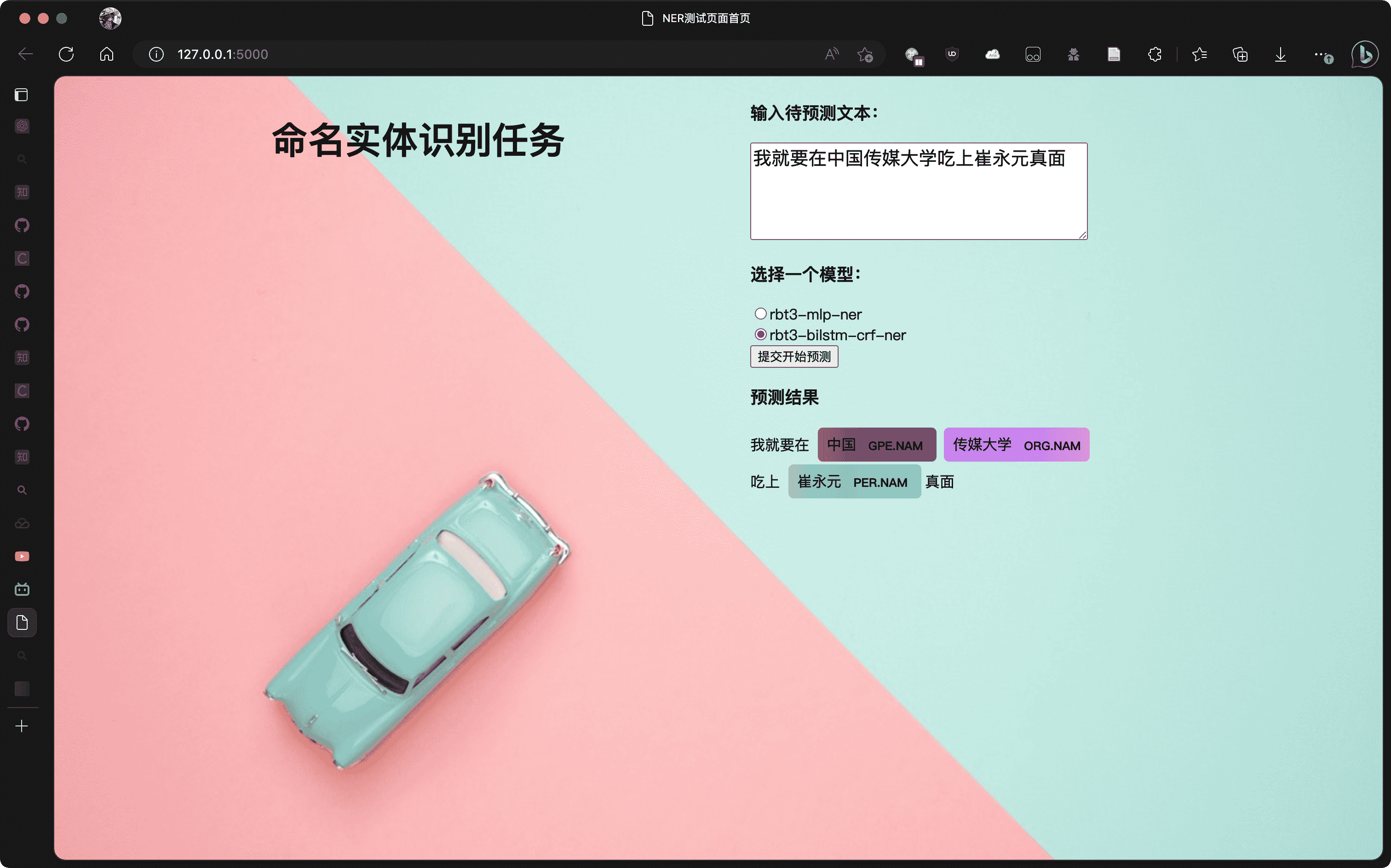
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from fastNLP.io import DataBundlefrom fastNLP import DataSet, Instancedef text2dataset (text:str ):if text != '' : list (text)))return ds'我今天就要在中国传媒大学吃上崔永元真面!' "predict" : text2dataset(text),print (predict_data_bundle)print (predict_data_bundle.get_dataset("predict" ))
结果如下,这里Instance对象赋给输入的列名是raw_words,和前面默认loader加载是不同的。
1 2 3 '我' , '今' , '天' , '就' , '要' , '在' , '中' , '国' , '传' , '媒' , '大' , '学' , ... |
构建dataloader
其实就是把前面的函数改一改,甚至可以将前面的函数加参数重构,重复使用。需要注意的是loader的列名不一样 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from fastNLP.transformers.torch import BertTokenizerfrom fastNLP import cache_results, Vocabularydef process_predict_data (data_bundle, model_name ):def bpe (raw_words ):0 ]1 for word in raw_words:False )len (bpe)return {'input_ids' : bpes, 'input_len' : len (bpes), 'first' : first, 'seq_len' : len (raw_words)}'raw_words' , num_proc=1 )return data_bundle, tokenizer'hfl/rbt3' )print (predict_data_bundle)print (predict_data_bundle.get_dataset("predict" ))from fastNLP import prepare_torch_dataloader1 )
结果如下,和前面的loader相比只是少了target一列,不过因为是做预测本身也用不到。
1 2 3 4 5 +--------------------- +-------------------- +----------- +-------------------- +--------- +--------------------- +-------------------- +----------- +-------------------- +--------- +... | [101, 2769, 791... | 22 | [0, 1, 2, 3, 4,... | 20 | --------------------- +-------------------- +----------- +-------------------- +--------- +
进行预测
第一种方法:Evaluator对象进行预测
通常的预测方法是构建一个evaluator对象用于调用模型的预测函数,这里需要加载数据集中的vocab用于进行idx2word 。
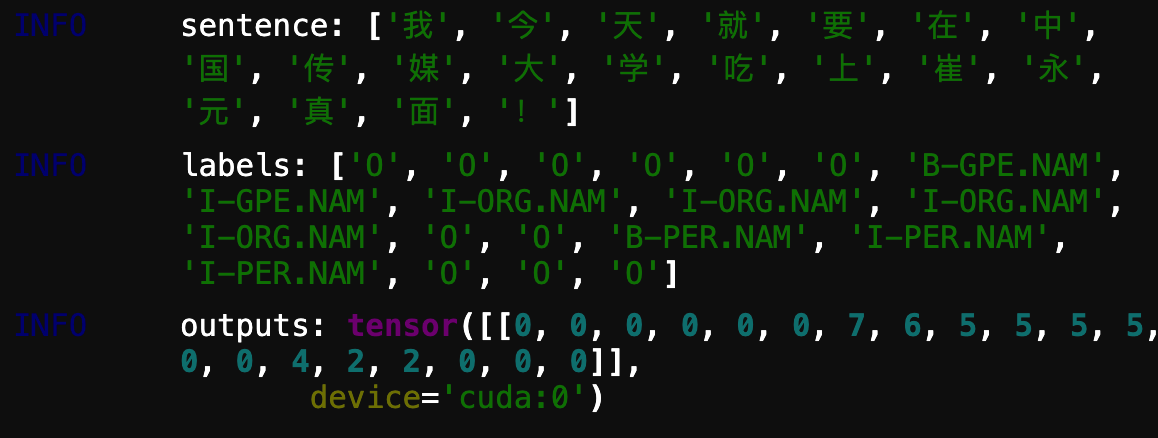
1 2 3 4 5 6 7 8 9 10 11 def predict_output_labeling (evaluator, batch ):"pred" ]"raw_words" ]for words, output in zip (raw_words, outputs):print ("sentence:" , words)"new_target" ).idx2word[idx] for idx in output[:len (words)].tolist() ]print ("labels:" , labels)print ('outputs:' ,outputs)"predict" ],0 , evaluate_batch_step_fn=predict_output_labeling)1 )
预测结果如下:
预测结果
这种方法查看预测结果是没有问题的,但是evaluator没有设置返回的参数,我们无法保存预测的结果用于后面部署可视化展示。
第二种方法:手动调用模型中的evaluate_step方法
考虑到我们部署的需求,需要提前将label和idx的对应关系提取出来,在预测后得到outputs列表后翻译成label。下面是一些工具函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 label_idx_list = list (data_bundle.get_vocab("new_target" ))def write_list_into_text (path,label_idx_list ):with open (path,'w' ) as f:for pair in label_idx_list:str (pair[0 ])+',' +str (pair[1 ]))'\n' )print ('write over!' )def read_list_from_text (path ):with open (path,'r' ) as f:for line in lines:',' )0 ],int (line[1 ])))return final_list'label_idx_list.txt' ,label_idx_list)'label_idx_list.txt' )def idx2label (label_idx_list:list ,idx:int ):None for pair in label_idx_list:if pair[1 ] == idx:0 ]return label
接下来很简单,将制作好的输入数据整理成tensor,调用模型的evaluate_step方法进行预测。
⚠️这里由于手动调用模型,一定记得使用eval函数将模型设置为评估模式,关闭dropout的影响。
1 2 3 4 5 6 7 8 9 dev = next (ner_model.parameters()).deviceeval ()for data in predict_dataloaders['predict' ]:'input_ids' ]).to(dev)'input_len' ]).to(dev)'first' ]).to(dev)'pred' ]
预测结果如下:
手动预测的结果
准备部署
将模型和txt文件保存好,到此为止模型的方面搞定了,接下来就是用flask搭建网页服务器的内容,内容太长,下一篇继续~