使用BERTopic提取文本主题
本文最后更新于:2023年3月31日 上午
使用BERTopic提取文本主题
加载数据集
挂载Google Drive用于读取数据集,这里会要求登陆Google账号授权,每次都需要重新授权,建议一开始在colab中选好gpu分配资源。
1 | |
数据集来自外卖平台中文评论,数据集地址:https://raw.githubusercontent.com/SophonPlus/ChineseNlpCorpus/master/datasets/waimai_10k/waimai_10k.csv,可以直接wget获取。该数据集本身用于情感二分类。
1
2
3import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/colab/waimai_10k.csv')
df['label'].value_counts()
结果为:
1 | |
0 表示负面评论
1 表示正面评论
不过这些label并不使用,只需要文本review
1 | |

将数据集整理为列表方便输入
1 | |
输出:
['很快,好吃,味道足,量大', '没有送水没有送水没有送水', '非常快,态度好。', '方便,快捷,味道可口,快递给力', '菜味道很棒!送餐很及时!', '今天师傅是不是手抖了,微辣格外辣!', '送餐快,态度也特别好,辛苦啦谢谢', '超级快就送到了,这么冷的天气骑士们辛苦了。谢谢你们。麻辣香锅依然很好吃。', '经过上次晚了2小时,这次超级快,20分钟就送到了……', '最后五分钟订的,卖家特别好接单了,谢谢。']
去除停用词(没用到,数据集已经过清洗)
1 | |
BERTopic建模
1 | |
使用sentence-transformers支持多语言的大模型进行embedding,在colab上下载速度很快,约400M瞬间完成。
1
embedding_model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
1 | |
聚类
1 | |
tokenizer 1
2from sklearn.feature_extraction.text import CountVectorizer
vectorizer_model = CountVectorizer()
1 | |
输入BERTopic模型 1
2
3
4
5
6
7
8topic_model = BERTopic(
embedding_model=embedding_model,
umap_model=umap_model,
hdbscan_model=hdbscan_model,
vectorizer_model=vectorizer_model,
ctfidf_model=ctfidf_model,
nr_topics=10
)1
topics, probabilities = topic_model.fit_transform(dataset)
可视化呈现和结果分析
查看聚类结果
1 | |
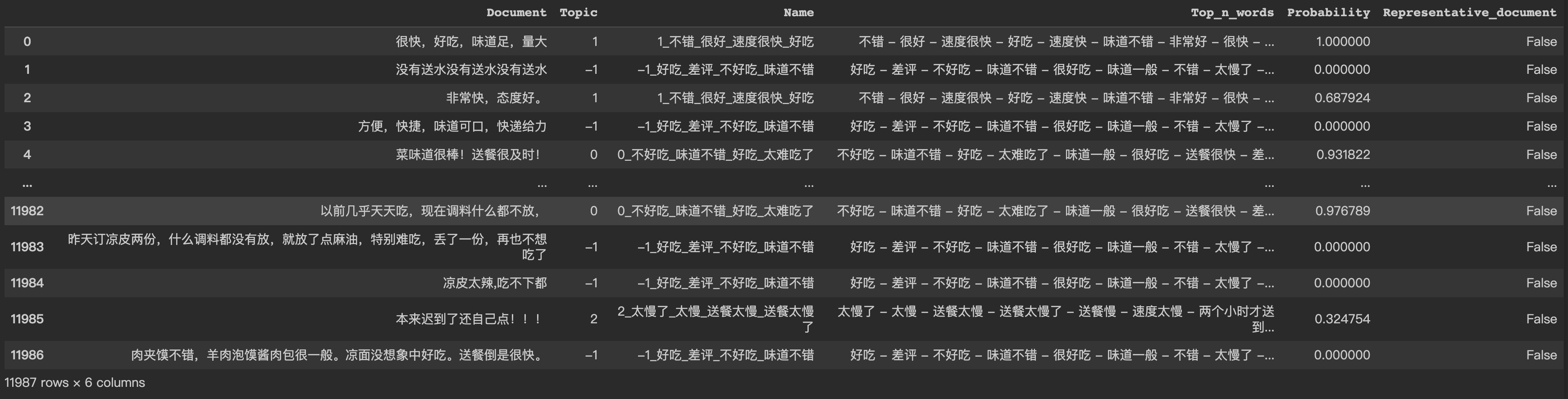
查看各话题文本数量。
-1表示没有聚类
1 | |
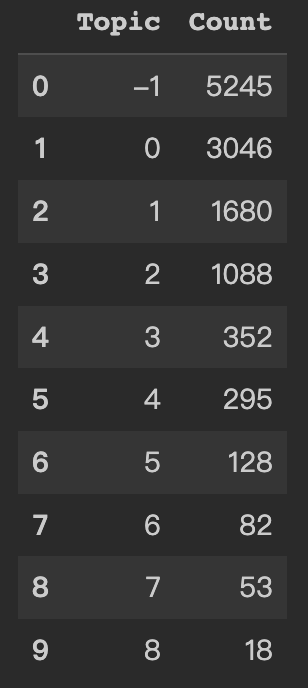
查看话题7的文本并按照重要程度排序
1 | |
可视化查看各话题分数排序
1 | |
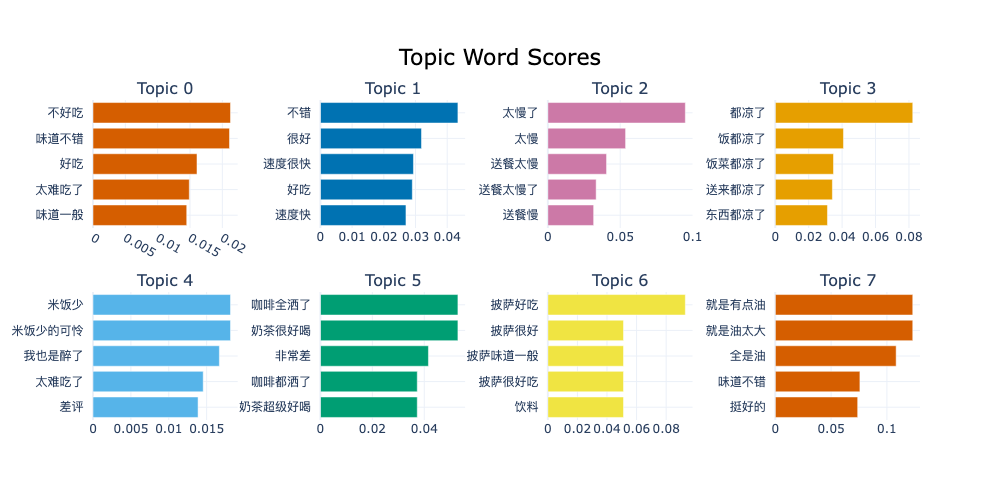
能够看到一部分结果聚类效果很好,比如集中描述送餐慢、凉、咖啡奶茶、披萨、油等主题,而其他一部分看起来好坏参半,原因应该是该主题聚类可能将评价好坏都列为“评价主题”而分到一起。
可视化呈现点云图
1 | |

点云图中颜色相同的属于同一主题,灰色属于无法聚类的文本。
可视化呈现热度图
1 | |
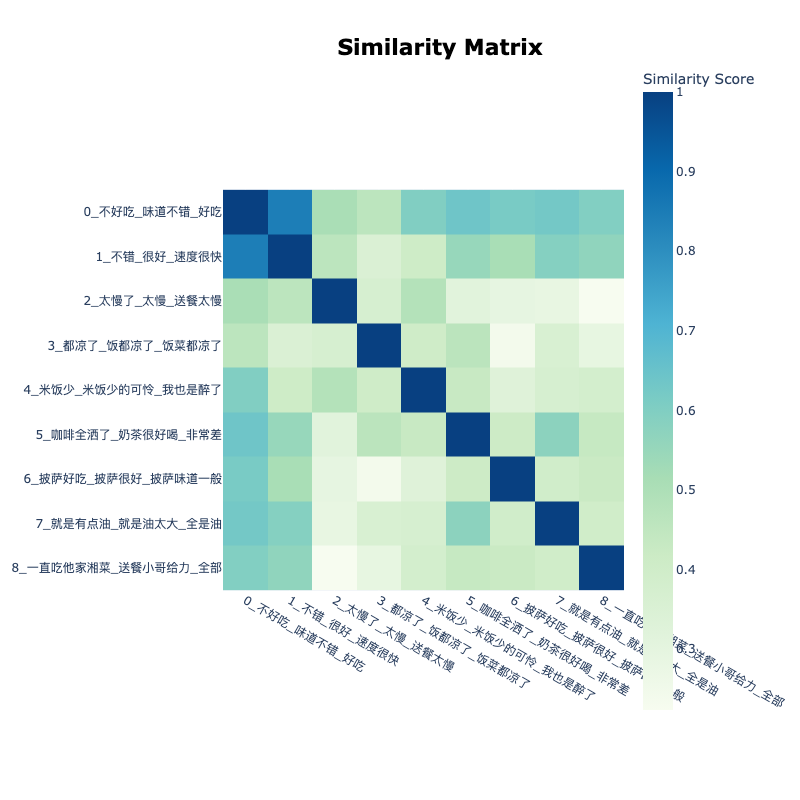
热度图中颜色相近的色块表示相似度高,可以看到01两主题的内容很相似,颜色较深;同时01两个话题与其他话题的相似度都很高;2号主题与其他的相似度较低,可以从颜色和文本中观察到。
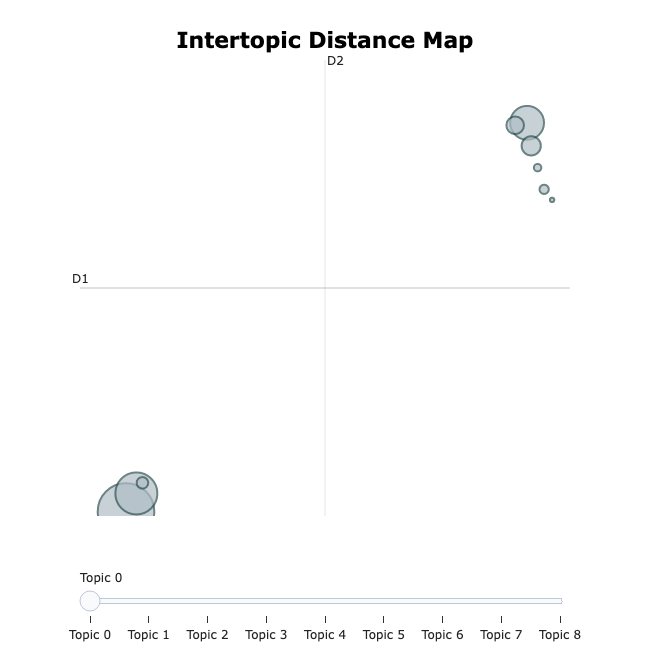
可视化呈现话题间距离
1 | |