本文最后更新于:2023年4月2日 下午
Fine-tuned Bert for
TextClassification
前言
文本分类也是NLP领域的传统任务,在Bert模型的加持下可以轻松达到较高的准确率,相比之前的NER任务从数据到模型上都要简单。
如果直接手写训练函数,可以在模型上调用huggingface的BertForSequenceClassification类,它是在BertModel的后面接上dropout和一层分类头,直接输出loss和logits,其他输出详情在huggingface官方文档。这里使用fastNLP框架,减去了手写训练函数和验证函数的步骤,就需要将模型单独实现,思路和前面一样,但需要变换下BertModel的输出。
外卖数据预处理
这次的数据集使用的是外卖平台的评论数据集,两个类别表示正向评论和负向评论,数据集按照
训练:验证:测试=7:1.5:1.5切分,总数据量约11800条。
需要用到tokenizer,所以在一开始就导入Bert模型加载BertTokenizer,BertModel。
1
2
3
4
5
| from fastNLP.transformers.torch import BertTokenizer
from fastNLP.transformers.torch import BertModel
tokenizer = BertTokenizer.from_pretrained('hfl/rbt3')
bert_model = BertModel.from_pretrained('hfl/rbt3')
|
预处理比较简单,数据集经过清洗,直接交给tokenizer做下encode,得到input_ids。
 数据集
数据集
然后放进databundle,指定vocab(其实只有两个类,也可以不用做vocab),放入dataloader做下padding,这是fastNLP的数据处理定番了,比之前NER的还是简单了不少。
模型搭建
这里搭建的模型跟前言提到的一样,就是在Bert的输出后加上全连接做分类头。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| import torch
from torch import nn
import torch.nn.functional as F
class BertClassifier(nn.Module):
def __init__(self,bert_model,num_class):
super().__init__()
self.bert = bert_model
self.mlp = nn.Sequential(nn.Linear(self.bert.config.hidden_size, self.bert.config.hidden_size),
nn.Dropout(0.5),
nn.Linear(self.bert.config.hidden_size, num_class))
def forward(self, input_ids):
with torch.no_grad():
outputs = self.bert(input_ids=input_ids)
last_hidden_state = outputs.last_hidden_state
last_hidden_state = last_hidden_state[:, 1:-1]
last_hidden_state = last_hidden_state.mean(dim=1)
pred = self.mlp(last_hidden_state)
return {'pred': pred}
def train_step(self, input_ids, target):
pred = self(input_ids)['pred']
loss = F.cross_entropy(pred, target)
return {'loss': loss}
def evaluate_step(self, input_ids):
pred = self(input_ids)['pred'].argmax(dim=-1)
return {'pred': pred}
model = BertClassifier(bert_model, len(data_bundle.get_vocab('label')))
|
模型训练
和NER文章中的一样,使用fastNLP框架训练很简单,只需要准备好数据的格式和列名。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| from torch import optim
from fastNLP import Trainer, LoadBestModelCallback, TorchWarmupCallback
from fastNLP import Accuracy
optimizer = optim.AdamW(model.parameters(), lr=2e-5)
callbacks = [
LoadBestModelCallback(),
TorchWarmupCallback(),
]
metrics = {
"acc": Accuracy(),
}
def input_mapping(data):
data['target'] = data['label']
return data
trainer = Trainer(model=model, train_dataloader=dataloaders['train'], optimizers=optimizer,
evaluate_dataloaders=dataloaders['dev'],
metrics=metrics, n_epochs=50, callbacks=callbacks,
monitor='acc#acc',device='cuda',driver="torch",input_mapping=input_mapping)
trainer.run()
|
这里metric中指定的是Accuracy,对分类任务求准确率,需要输入列名为target和pred的数据,所以多了一个input_mapping函数做预处理,也可以提前在dataset或者dataloader时做好处理。
fastNLP在evaluate过程中可以直接输入形如[batch,]的label数据,所以前期不用手动将label转为one-hot向量,这一点方便了很多。
训练结束后由于LoadBestModelCallback会自动加载最佳模型到model中。
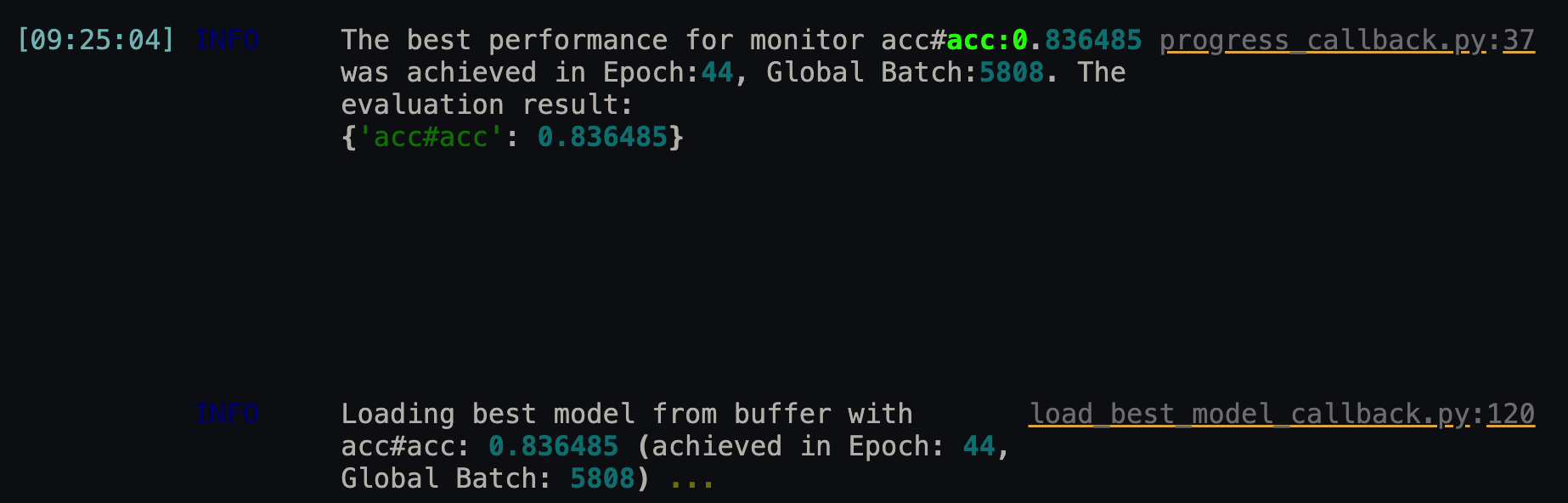 训练完成
训练完成
最后得到在验证集上的准确率0.836485
模型测试
1
2
3
4
5
| from fastNLP import Evaluator
evaluator = Evaluator(model=model, dataloaders=dataloaders["test"],metrics=metrics,callbacks=callbacks,
device=0, input_mapping=input_mapping,evaluate_batch_step_fn=None)
evaluator.run(1)
|
输出测试集上准确率:这个模型结果为0.8125
TNEWS'数据集测试
最后用CLUE上的基准数据集做下测试,使用今日头条新闻数据集TNEWS'。共有15个类,表示新闻的不同类别,训练集53k,验证集10k大小。数据格式如下:
1
2
| {"label": "102", "label_desc": "news_entertainment", "sentence": "江疏影甜甜圈自拍,迷之角度竟这么好看,美吸引一切事物", "keywords": "江疏影,美少女,经纪人,甜甜圈"}
{"label": "110", "label_desc": "news_military", "sentence": "以色列大规模空袭开始!伊朗多个军事目标遭遇打击,誓言对等反击", "keywords": "伊朗,圣城军,叙利亚,以色列国防军,以色列"}
|
验证集上最终准确率为0.5112,相比二分类难度确实更大。