Python中GB2312转UTF-8的问题(2023.07.31)
本文最后更新于:2023年8月6日 晚上
问题描述
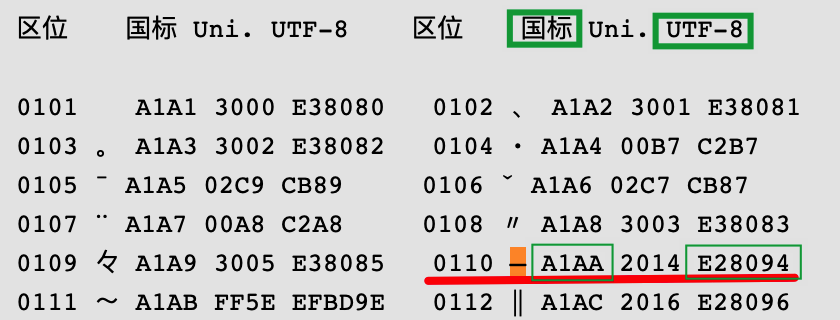
中文的单个破折号—字符在GB2312编码中使用两个字节,十六进制表示为A1AA。
根据这幅图中的对应关系在UTF-8编码中应该使用三个字节E28094(VSCode内置的通过编码保存功能得到的也是这个结果)
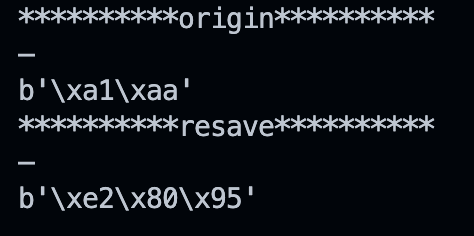
是在通过Python的open函数读取GB2312文件并重新保存为UTF-8编码时,结果变成了E28095,成为了另一个长相相同但是编码不同的字符。
接下来我们查询一下UTF-8中这些字符真正对应的内容,UTF-8编码查询参考网站
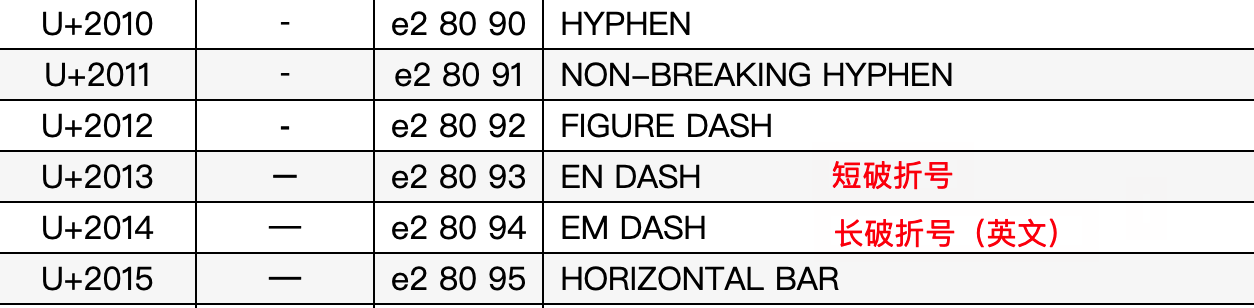
可以看到这里E28090-E28096都是不同长短的折线。
我在Edge浏览器中使用搜索工具搜索中文破折号(Shift-),这时候打出了两个相同字符,删除其中的一个,高亮显示都是E28094字符的破折号,看起来是微软统一使用该转换方式,而Python选择了另外的转换方式,本身不是大问题,但是可能会导致意料之外的结果。
结论
在涉及到中文字符的编码和处理时最好统一先全部处理为相同的固定格式,并且做好清洗和预处理工作,防止意料外结果出现。
Python中GB2312转UTF-8的问题(2023.07.31)
https://ash-one.github.io/2023/07/31/python-zhong-wen-jian-bian-ma-du-qu-he-bao-cun-cun-zai-de-wen-ti-2023-07-31/